From A to B, Ranges in C++
C++ is all about performance achieved through detailed programming and carefully
aggressive compilation.
The standard C++20 introduced
Ranges
which were proposed by Niebler, et al.
[3].
The idea is simple, instead of passing a begin and end iterator to an algorithm,
pass a single object
including
both.
The object adopts the mathematical notation of interval: [begin,end).
Niebler, et al. also proposed how ranges can be generated with
range adaptors
.
There is no doubt that the increasing adoption of functional programming by
mainstream computing has left its mark in C++.
Range adaptors are lazy and borrow names from well-known functions like take,
filter, zip and so on, present in any functional programming language.
Later Revzin [2] found that given auto a = views::iota(0) | views::reverse;
the call a.begin(); would not terminate.
To address this issue, Müller [1] proposes to introduce the C++ concept
of
infinite range
.
Concepts were included formally in C++20 as well.
A concept is a predicate over a template's parameters that is evaluated at compile-time,
so an
infinite range
concept implies testing for infiniteness at compile-time.
I would like to dig a bit deeper into the range concept, Revzin's example and
Müller's proposal. I will start with the iterator and range concept, then a few
observations about Revzin's example and similar examples pointed by Müller, some
simple but cumbersome compile-time solutions and examples that may not be possible
to be detected at compile-time, I will also show a 'counter-intuitive' example
that should not work but
does
. Finally I will conclude with a notion of
infiniteness that is based on the level of amnesia of a range generator.
Ranges are easier to understand if we consider two different
universes
.
One is a numerable and totally ordered universe of indices (pointers, iterators, tags, etc.)
and the other a
universe
of data. We can depict both as:
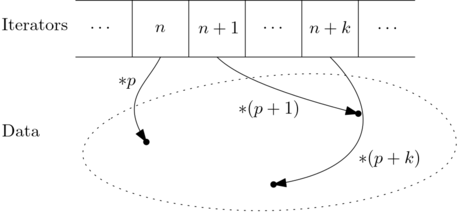
The operation * is used to travel from the Iterators universe into the Data
universe, in other words, return the data the iterator points to.
Since iterators are numerable we can talk about the successor of an iterator and
because they are totally ordered, we can ask questions like: is iterator a before
iterator b?
A range is then only a continuous subset of the indices universe.
The following image depicts the induced range ([begin,end)) of a typical pair of iterators
used in algorithms.
One marks the start of the data (begin) and the other marks
the first iterator pointing to data NOT to be considered
(end).
In other words end is the least upper bound of the set of iterators of interest.

The standard C++20 defines a valid range as:
A sentinel s is called reachable from an iterator i if and only if there is a
finite sequence of applications of the expression ++i that makes i == s.
If s is reachable from i, [i, s) denotes a valid range.
[4]
This definition is equivalent to the procedural definition: a range is
valid
iff
exists k >= 0 such that the following program terminates:
i = begin(); while(k > 0){ i++; k--; } while(i != end());
There is a small caveat when begin and end are equal ([begin,begin))
on the one hand, the range includes begin, on the other hand it does not!
This is why in my procedural definition k is allowed to be 0 but checked for
positiveness during the while loop.
Ranges are modeled after iterators and iterators are modeled by the Iterators
universe, then it makes sense ranges like [a,b) where b < a are invalid.
In the idealized Iterators universe, if b < a the equation b = a + k where
k is a natural number, does not have a solution.
In my procedural definition, if we assume we have as much memory as we need
(i.e. infinite memory) then for any k >= 0, the program
i = a; while(k > 0){ i++; k--; } while(i != b); will not terminate when
b < a.
I have mixed no-termination on purpose to emphasize that no termination is not
unique to infinite ranges.
Of course we must remember that if we adopt ranges, we are only obliged
to handle
valid
ranges, if we are given an invalid range, we are free to
have undefined behavior.
But an infinite range, one in which end is really so far to the right of begin
makes complete sense because it allows to model streams and infinite processes.
Revzin's example auto a = views::iota(0) | views::reverse; a.begin(); never
terminates.
It never terminates because views::iota(s) initializes the
associated range to be [s,unreachable_sentinel_t), that is, it will
start at s and C++ will guarantee the end is never reached.
Since views::iota() is lazy no computation is performed and it can be
queried as long as needed.
However when composed with views::reverse, the induced range becomes
[unreachable_sentinel_t,s] (note the brackets).
When a.begin(); is called, then, since unreachable_sentinel_t is not
operable
, the computation falls back to increment s in the hopes to
find the end and finally find the first element of the reversed interval.
But C++ makes sure that end is never reached and hence an infinite loop is triggered.
There is an inconsistency between how range adaptors (generators) work and the
definition of
valid
range.
If you are compelled to work with valid ranges, and views::iota(0) clearly
induces an invalid range, then why care at all?
But if this is true, then why defining unreachable_sentinel_t at all? any
interval that uses it is invalid and hence nothing would work reliably!
So, either infinite ranges are precisely adopted or banned.
To me, this is reason enough to either propose an infinite range definition or
argue against it; to be precise in the language.
"What is the size of an infinite range?" this is a seemingly dumb question.
But I wanted to know C++'s answer to auto a = views::iota(0) | views::reverse;a.size(); a.begin();.
Particularly I was interested to know if a.size(); would trigger a computation.
It didn't; it simply fails to compile.
This is interesting because a simple patch for any method that gets a view and
won't work with intervals including unreachable_sentinel_t can simply do
v.size(); as a first call.
If we assume size() is a function without side-effects and that the result
is not used anywhere in the rest of the method, then an optimizing pass can
remove the call altogether.
I ran a few experiments with Revzin's example but over valid ranges and found
that calling size increases the running time by about 6.7 percent.
With these observations I would consider the matter of intervals using
unreachable_sentinel_t for infinity closed.
Yes, the solution is cumbersome, but it is achievable by the language current
capabilities, which means the necessary bits
to detect them are already present and introducing new concepts is not necessary.
Even the example views::zip(views::iota(0),views::iota(1)) introduced by Müller
[1] fails to compile with the simple patch.
The next question is: shall all possible infinite intervals use unreachable_sentinel_t?
Before addressing this question I want to look a bit closer at Revzin's example.
The views::iota constructor expects two arguments but requires at
least the first. [5]
The first argument must be
weakly incrementable
and the second
semiregular
.
When the second argument is not given, it defaults to unreachable_sentinel_t.
A
weakly incrementable
type can be moved (not relevant to us right now),
must have pre and post-increment operations defined and those are not required to
preserve equality, finally, they must
behave
as integers [6]
(also not relevant to us right now).
This now explains a bit better the line views::iota(0); the type that the
compiler assigns to 0, normally int, is
weakly incrementable
and
the second (template) argument defaults to unreachable_sentinel_t.
Up to this moment there is no
type
relation between views::iota and
a range.
In the documentation [5] views::iota is equivalent to views::iota_view
and views::iota_view is defined as a
range factory
.
Moreover views::iota is defined as a
customization point object
but
neither of them directly mention ranges, with the exception of views::iota_view.
At this point, without digging into a specific implementation I will adopt
Revzin's definition of views::iota(0) [2] and the definition of
adaptors given in [3].
Therefore, views::iota(0) is a range, but Revzin's mentions it is a non-common
range [2].
A range is non-common when the methods begin() and end() return different types.
That is, the range
starts iterating
over one type and
stops iterating
over another.
This definition presents a problem to the interpretation of Iterators universe
because it is possible to have (at least) two parallel Iterator universes
without a clear (from the ranges point of view) map between them.
The user has no control over the generated range only over the start value and
the upper bound, it is not clear but implied that the upper bound must be
reachable but not included in the output.
As far as I could see at [5], arguably one of the best resources to
consult C++ documentation, there is no functional definition of iota_view nor
iota.
I think the lack of documentation combined with the freedom on the iterators types
(the lack of an specified map between the types) opens the door for reasonable
use-cases that, by definition, will present undefined behavior.
I will construct a circular (modulo) counter that fits the intuition of
iterators but that behaves exactly as Ravzin's example because the range is not valid.
From that example we can presume and wrongly conclude that reversing is
constructed incrementally. I will create another example that shows the construction
happens using decrements when the type of the bound is the same as the type of
the initial value, but yields wrong results as well.
I think these examples (specially the first one) are reasonable.
Let's start with the first example:
// circular_infloop_iota.cpp
// A range from a circular counter with well-defined upper limit.
// An example of an infinite computation that does not depend on how increment
// of primitive variables is defined at the hardware level.
#include
struct CCounter
{
unsigned cval;
unsigned _size;
using difference_type = int;
// Custom constructor definition
CCounter(unsigned cval, unsigned size):cval(cval),_size(size)
{ assert(cval < size); }
//Required definition derived from the definition of Custom
CCounter(){ CCounter(0,1); }
CCounter& operator++()
{
cval = (cval == _size - 1)? 0 : cval + 1;
return *this;
}
CCounter operator++(int)
{
CCounter t = *this;
cval = (cval == _size - 1)? 0 : cval + 1;
return t;
}
CCounter& operator--()
{
cval = (cval == 0)? _size - 1 : cval - 1;
return *this;
}
CCounter operator--(int)
{
CCounter t = *this;
cval = (cval ==0)? _size - 1 : cval - 1;
return t;
}
bool operator==(unsigned x) const {return x == cval;}
bool operator==(const CCounter& g) const {return cval == g.cval;}
};
int main()
{
auto g = CCounter{0,3};
auto a = std::ranges::views::iota(g,3) | std::ranges::views::reverse;
a.begin();
return 0;
}
The variable g holds a counter that can count from zero to two.
The definition views::iota(g,3) looks similar to something like v.begin(),v.end().
The operation *v.end(); makes no sense but *(v.end()-1); does.
Similarly 3 in the context of g makes no sense, but 2 does.
This example, like Revzin's does not terminate. However, if we change the upper
limit and use the same type as g the situation changes.
If we define auto l = CCounter{3,4}; using it as upper bound in a's
definition and replace a.begin(); by
for (CCounter i: a) i.cval the code behaves as expected; the indefinition
coincides with the expected output.
On the other hand, if we define auto l = CCounter{4,5}; instead, the
code also terminates but it gives the wrong output (with respect to g) but
correct with respect to l, that it, it returns 3,2,1,0.
This last output shows that views::reverse uses l's decrement definition
until its equality operator returns true when the counter values of g
and l are the same.
These examples do not induce an infinite range. In the first case, the range is
also non-common but in the second case it is a common range.
In both cases, the ranges are invalid but almost
problem-domain coherent
.
In the first example, the 3 in views::iota(g,3) is a value that can not
happen in g but it is an upper bound of g, in fact, it is the least
upper bound of g.
If we want to express the number 3 using CCircular the smallest size we must
use is 4, this puts both objects g and l on different problem-domains.
Problem-domain equality is sound, it compares the actual value.
We can tweak the equality operator to compare the values iff the counters are of
the same size.
But that would be the equivalent of not being able to compare for equality an int
and a char.
In the second example, the type is the same, and since a CCircular counter of
size n completely contains one of size m iff n <= m, then the code
terminates.
It seems views::reverse assume the increment operator is inverse of the
decrement operator so it decrements instead of incrementing.
It seems the arguments of a range producer, at least in the case of views::iota,
must fulfill the properties of a valid range, this is not inherently bad, I just
wonder if it would not be more suitable to create a
range-like
type for
data and hence enforce it with the compiler.
On the other hand, I think it could be worth exploring what are the gains, beyond
the syntactical sugar, of enforcing range-like behavior on data underlying range
generators over the regular use of begin() and end() iterators.
If we assume all range producers require valid
range-behaved
data is it
necessary to define a concept of infinite range?
Infinite ranges sound tricky because data may
wrap
around.
In all examples, the range producers circular outputs; after
a period they repeat themselves.
Infinity detection is then reduced to the ability to detect circularity.
Detecting circularity has more applications, it allows to detect upper bounds,
in other words it expands the concept of valid range.
A valid range [a,b) becomes one such that b is an upper bound and
unreachable_sentinel_t is the top element, it is the upper bound of any upper bound.
An advantage of upper bounds is that [a,b] is well defined, b is an upper
bound that is also inside the set.
Care must be taken because unreachable_sentinel_t should not be generated,
that is, any range data generator should never return an element of
unreachable_sentinel_t.
The problem with circularity are the checks induced to detect it.
This open the usual dimension of bounds checking: 1) if the user defines a data to
be infinite, then no check is required, 2) if it is defined as finitely bounded but
not reachable ([a,b)) then checks for circularity must be performed
3) if it is defined as finitely bounded and reachable ([a,b]) then only
equality much be checked.
For this concept to work with the usual begin() end() constructs, two
equivalent ranges would be possible: 1) [a,b-1] or 2)[a,b).
I think bounded ranges decouple the data producer from iterator handling, allowing
more flexibility on its application.
[1] Jonathan Müller, "An infinite range concept", https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2025/p3555r0.html#ref-P3230R1
[2] Barry Revzin, "Reversing an infinite range leads to an infinite loop", https://cplusplus.github.io/LWG/issue4019
[3] Niebler,E., et al., "Ranges for the Standard Library, Revision 1", https://isocpp.org/files/papers/n4128.html
[4] https://en.cppreference.com/w/cpp/iterator.html#Ranges
[5] https://en.cppreference.com/w/cpp/ranges/iota_view.html
[6] https://en.cppreference.com/w/cpp/iterator/weakly_incrementable.html
Copyright Alfredo Cruz-Carlon, 2026